The Evolution of Smart Contracts in the Design of Move’s Architecture
This article attempts to analyze Libra’s Move contract from the perspective of the evolution of smart contracts and its architectural design, that is, to answer the question “Why did Libra redesign a programming language? That is, to answer the question “Why did Libra redesign a programming language?
What is a Smart Contract?
Before we start this topic, we can discuss a bigger topic, what exactly is a ‘smart contract’? In fact, the term ‘smart contract’ is very controversial in the industry, and everyone has his or her own opinion. For the sake of discussion, let’s give it a qualification in the context of the current topic.
- User-defined programs that run on a chain
- Independent and binding without relying on the authority through repeated verification of chain nodes and consensus mechanism
First of all, it is a program that runs on the chain and is customized by the user. If it is implemented directly on the chain, even though the mechanism of a plugin, we do not call it a smart contract here. Secondly, because of the chain’s repeated checks and the consensus capability, makes such programs are binding. This binding force does not come from your trust in a particular party, even the developer of the contract is bound by this binding mechanism.
As for the controversial points about “smart contracts”, I won’t discuss them in-depth here, but if you are interested, you can read my previous article on smart contracts from the perspective of “legal contracts” — What is a smart contract?
Reviewing the evolution of smart contracts
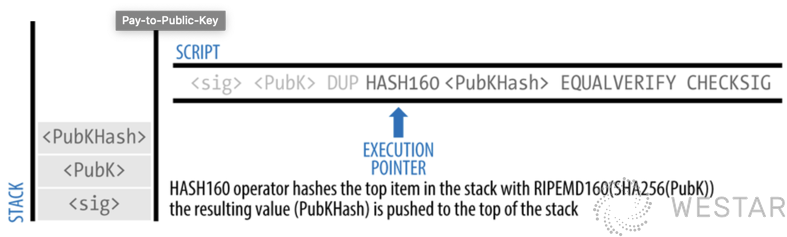
(Image source: Mastering Bitcoin 2nd)
Bitcoin’s smart contracts are the Locking & Unlocking Script that locks and unlocks assets. Simply put, Bitcoin provides a smart lock that users can assemble to lock or unlock assets according to their needs.
So why doesn’t it just define a way to lock and unlock, but make it very scriptable for users to customize? The main purpose is to provide logical extensibility to the chain so that users can add some features and do some experiments without changing the base code of the chain. At the same time it is stateless (Stateless), a lock only manages one asset, and no data can be shared between locks. It is also designed to be Turing Incompleteness to avoid users to write too complex locks to increase the cost of unlocking the chain.
Bitcoin itself defines a clear application scenario, whether it is understood as a cryptocurrency or a cryptographic asset, the main function is to preserve assets and transfer them. This design also meets the needs of its scenario. As long as the asset transfer contract can be expressed through locks and unlocks, it can be implemented with Bitcoin’s smart contracts. But not all contracts can be expressed through locks and unlocks? This remains to be proven. It is very challenging to design a set of protocols for locking and unlocking, such as the protocol for the Lightning Network. For more information on the different locking mechanisms on Bitcoin, see an interview with Lee and me — “The Three Locks That Unlock Bitcoin Smart Contracts”.
Bitcoin provides such a decentralized bookkeeping capability, that users will wonder if they can use it in other ways. For example, if a Hash of data is used as an address, and a small amount of assets is transferred to that address, the Hash address is publicized on the chain, providing proof of the existence of the data. But there is no way to spend this money because no one knows what the private key corresponding to this Hash address is. If there are more transactions like this, it will put a lot of pressure on Bitcoin’s chain, which has to maintain all the unspent transactions (UTXO).
So Bitcoin developers came up with a way to add a directive OP_RETURN. instead of disguising their data as an address, users can directly embed their data in a script and then add OP_RETURN so that the chain knows that the transaction will not be spent in the future, but simply record the data in the block. And with this mechanism in place, more and more third-party developers are trying to use Bitcoin’s network to issue another asset, which is often referred to as Colored Coins. The issuer only needs to run some nodes to access the Bitcoin network and verify the data in OP_RETURN, which is much cheaper than running a chain independently. Then, if the script can read and generate the state, is it possible that such verification nodes are not needed and can be directly delegated to the chain for verification? This gives birth to Ethereum.
Ethereum’s Smart Contracts
Ethereum’s smart contracts are stateful and Turing-complete. For example, look at an example of a Coin given on the community’s official website (with simplifications) :
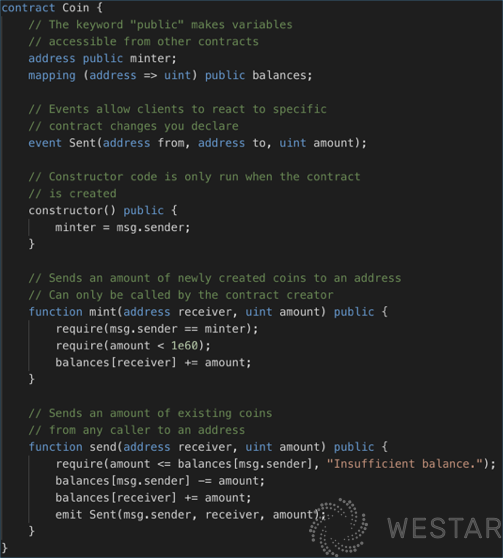
In this example, the balance in the Coin contract is a map that holds a mapping of the user’s address and balance, and when transferring money, you can just decrease the sender’s balance and increase the receiver’s balance. Seems pretty simple, right? It looks like a stand-alone program that can be understood by anyone who knows a little programming language. But to provide this kind of capability, there are a number of challenges that need to be solved, and Ethereum’s solutions are important innovations in the blockchain smart contract space.
Turing completeness and downtime issues
Since it is a Turing-complete language, it needs to solve the problem of downtime. If someone writes a dead-loop contract and puts it on the chain, then all nodes enter the dead loop. And according to the proof of the downtime problem, there is no way to determine whether it will enter a dead loop by analyzing the program directly, that is, there is no way to prevent users from deploying such a contract to the chain in advance. So Ethereum designed a gas mechanism, which requires a portion of the gas to be consumed when executing each instruction, and when the gas is consumed, the contract will fail to execute and exit. This is a very classic innovation.
State storage of contracts and consistency check of node states
The script in Bitcoin is stateless, its state is just UTXO, and each node maintains its own list of UTXOs. But Ethereum’s contracts are stateful (the data stored in the contract, such as each person’s balance in the previous example) and can be changed through transactions.
To solve this problem, Ethereum has designed a state tree:
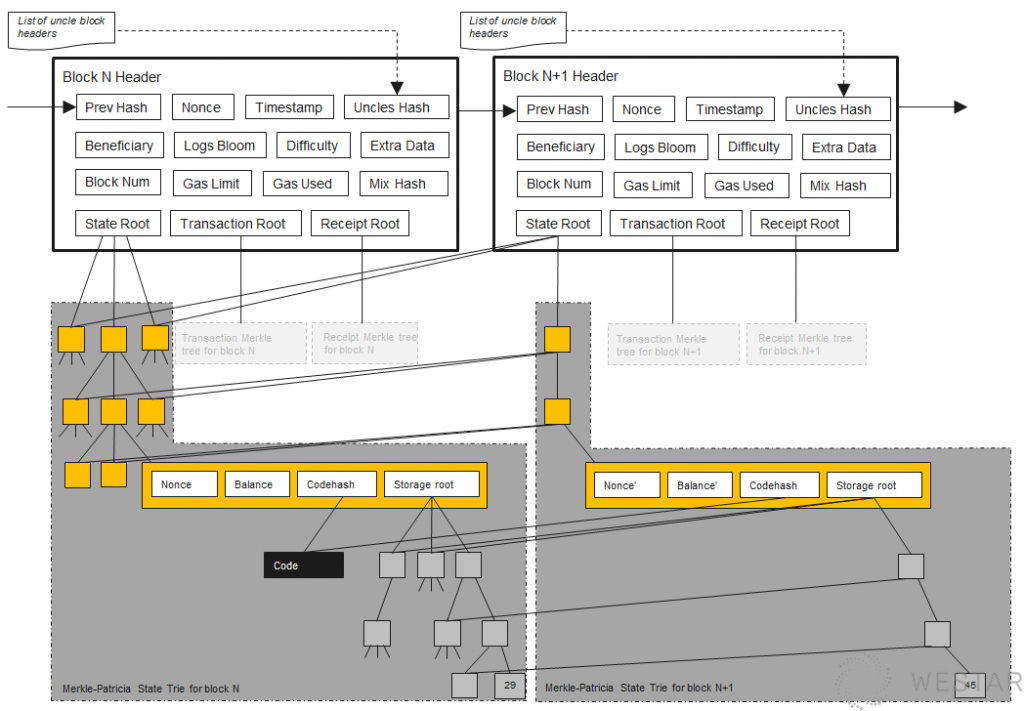
(Image source: Ethereum StackExchange Ethereum-block-architecture)
The whole idea is that each external storage variable in each contract is represented as a node in the state tree. All the variables in a contract generate a state tree, and the root node is the Storage Root, which in turn is mapped to the Global Storage Root by the contract address. Whenever any variable in any contract changes, the Global Storage Root changes, and the consistency of the data can be quickly verified by comparing the Global Storage Root between nodes. It also provides a state-proof capability that allows nodes to trust each other’s state data and quickly synchronize node states instead of computing them all over again through the block.
The Merkle Patricia Tree is not described in detail here, but you can read Ethereum-related books or articles if you are interested.
Contract abstraction and cross-contract calls
Since Solidity which is provided by Ethereum, is a complete programming language, there is the issue of abstraction and inter-call, and Solidity is designed with Interfaces, similar to those in other programming languages. Developers can negotiate to define an Interface as a standard and then implement it individually. Interfaces can be called between contracts, and between contracts and clients (e.g. wallets).
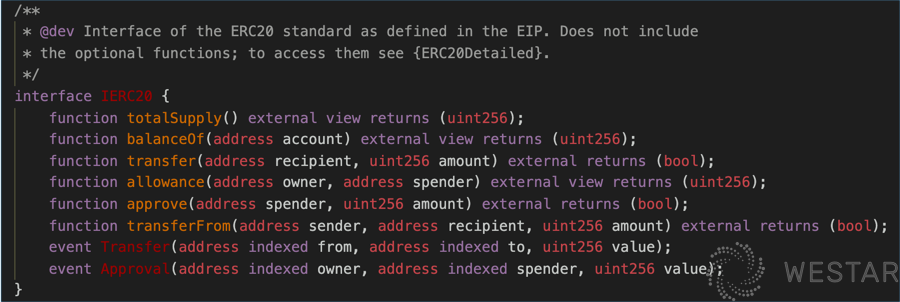
The ERC20 interface above, for example, defines standard methods for transferring funds, checking balances, and so on. The purpose of approval is to give a third party authorization to debit money from the user’s account, similar to the credit card pre-authorization mechanism. Community developers can propose an ERCxxx if they have a new idea, and others can further combine and innovate based on this ERCxxx. This mechanism is very flexible, and the thriving Defi ecosystem on Ethereum mainly relies on this mechanism to evolve.
Problems with Ethereum
Of course, there is no perfect technology, and Ethereum offers some new capabilities, but also some new problems.
Inconsistent abstraction and behavior between on-chain native assets (Ether) and assets defined by contract (ERC 20 Token)
This is something that people who have written Ethereum contracts will know very well. If you have to write a contract that handles both Ether and other Tokens, you will find that the logic of the two is completely different and it is difficult to handle them in a uniform way. The security of Ether is guaranteed by the chain, while the security of Token depends on the developer of the Token. For example, in the layer2 scheme of Ethereum, it would be complicated to support both Ether and Token.
Security
Many security incidents have broken out on Ethereum, and while the immediate cause of many of the problems is a lack of rigor in the contract developer’s implementation, the essential cause comes from two things:
- The tension between scalability and determinism
The Interface mechanism provides great extensibility, but Interface only defines the connection and does not guarantee that the implementation will follow the interface requirements. For example, here is an example of a spoof Token I once developed:
The transfer method of this Token contains a random mechanism that has a certain probability of successful transfer, but also a certain probability of increasing its own Token. This behavior is hidden by the transfer of the Interface, so that the caller is not aware of its implementation, which may cause security problems.
Of course, one way is to directly implement a Token with a defined logic that does not allow users to customize the logic and only provides limited configuration items, such as total amount, name, etc. Some chains do this in order to solve the security problem of Ethereum. However, this does not allow users to scale according to their own scenarios, such as implementing a Token that is only available to a certain group of users, and there is no way to exhaust this scalability requirement, so users have to keep trying to evolve. This is the paradoxical dilemma between scalability and determinism.
- Inter-contract call issues
The call between contracts on Ethereum is a dynamic call. It actually constructs an internal transaction and then starts a new virtual machine to execute the call. The mechanism I s a bit like a remote call between servers, and such calls can potentially form circular calls, resulting in a concurrency-like situation, even if the VM is executing in a single thread. For example, contract A calls contract B, which in turn calls back to contract A. The previous execution of contract A is then called. So the previous execution of contract A is not yet complete and the next execution is performed, while the second execution cannot read the intermediate state of the first execution. This is the vulnerability that the DAO attack exploited. The analysis of this problem can be found in the paper A Concurrent Perspective on Smart Contract.
- Contract Status Explosion
The main reason for the explosion of contract state is that Ethereum, while designed with a gas fee mechanism, avoids users abusing the network. However, this gas is only for computation and is a one-time charge. Once data is written to the contract state, it is retained forever, and users do not have to bear the cost of the future storage of their data. This results in neither users nor developers having an incentive to clean up the useless state. At the same time, all user states of the same contract in Ethereum are under that contract account, and the data under popular contracts will swell even more.
Ethereum developers tried to implement a mechanism of state leasing, allowing users to pay state fees for their state, but all users’ states are stored under the contract account, and it is difficult for the chain to clarify the relationship between state and users, and it is impossible to distinguish between those that are public states of the contract and those that are specific users’ states, so the scheme is very complicated to design, and finally gave up and put this goal in Ethereum 2.0. Interested readers can see a version of the Ethereum state fees scheme.
Think about a few of the problems left over from Ethereum above, and how you would solve them if you were designing a solution. Later, we will analyze how Libra’s Move solves these problems.
Libra Move
These are a few characteristics of Move that I have summarized:
- First-class Resources
- Abstract by data not behavior, No interface, No dynamic dispatch。
- Use Data visibility & Limited mutability to the protected resources, No inheritance.
First-class Resources contain two layers of meaning. On Libra, all assets are contractually implemented, including LibraCoin, and all share a set of abstract logic and security mechanisms with equal status. The second layer is that the assets in Move are of a type defined by Resource and can be referenced directly in the data structure.
The second simple understanding is that it discards the interface mechanism. But without an interface, how do we define protocols and standards? Exactly how it is abstracted through the data, will be discussed later.
The third understanding states that since an asset is a data type and cannot be hidden inside a contract, by what means is it protected? For example, by preventing users from directly adding a new asset?
Before we understand how Move solves the above problem, let’s understand the basic concepts in Move.
Basic concepts in Move
Module, Resource | Struct, Function
Module is similar to modules in other languages, such as mod in Rust and Contract in Ethereum Solidity, in that it encapsulates a set of data structures and methods. Function is not very different from Function in other languages.
Copy, Move
This is a concept introduced by Move, borrowed from Rust’s lifecycle mechanism. All variables in Move need to be determined whether they are to be moved or copied when they are used, and once they are moved, they cannot be used again. Once a variable is moved, it cannot be used again. A Resource can only be moved but not copied, although the Reference of a Resource can be copied. This allows the compiler to track the transfer and change of assets in the same way as it tracks memory usage so that assets do not disappear or are created out of thin air.
Builtin Methods
Move provides some built-in methods to interact with the state of the chain, and in Solidity, the developer hardly needs to care how the state of the contract is stored and persisted, almost transparent to the developer. In Libra, however, the developer has to explicitly call methods to get the state externally. This forces the developer to explicitly split the state under a specific account when writing the contract in order to implement the state leasing and elimination mechanism.
- borrow_global(address)/borrow_global_mut(address) Get a reference to a Resource of type T from the address account
- move_from(address) moves Resource T out of the address account
- move_to_sender() stores Resource T under the sender’s account of the transaction
T in the above example must be the type defined by the current Module, and a Module cannot directly get the type defined by other Modules. Let’s understand the mechanism of Move by some concrete examples.
An example of one
This example is the definition of LibraCoin.
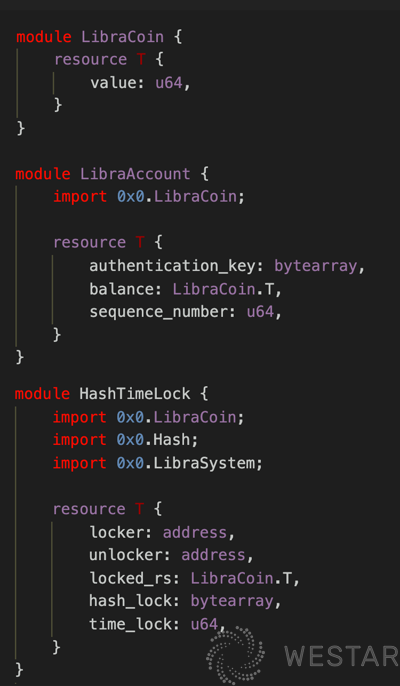
For example, the LibraCoin module above defines a resource type T, which represents a Coin and contains only a number inside, representing its value. In LibraAccount and HashTimeLock, LibraCoin.T is directly referenced as a field of its own type. The difference between Move and Solidity is that in Solidity, a Coin is a contract, and there is no data type for a Coin. So how does a Coin define its own behavior after this definition? How does the user use it? See the following example.
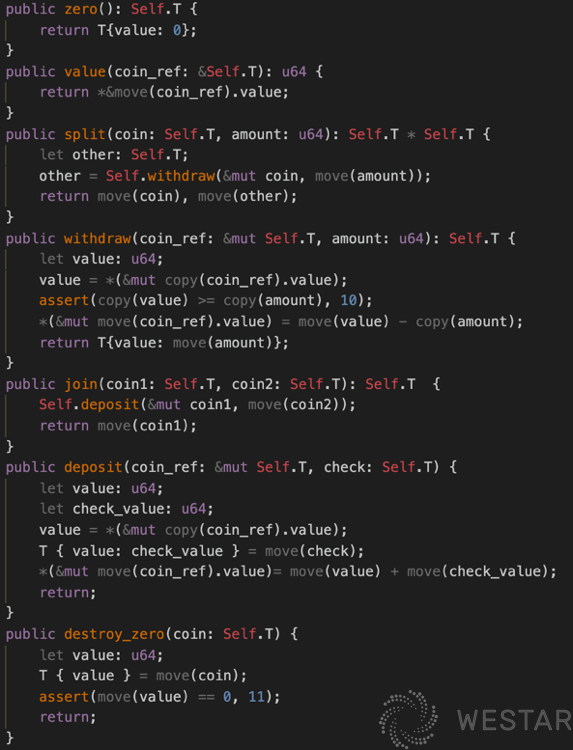
The LibraCoin module defines the most basic methods of LibraCoin. The deposit and withdrawal methods in LibraCoin are not specific to the account but are references to LibraCoin. In Move, the internal structure of a Resource is only visible to the module that defines it, and external modules can only treat a Resource as a whole, and cannot directly perform operations like splitting and joining.
How is the Coin defined in the contract issued? Since it is a type, how can we control the authority of Coin issuance?
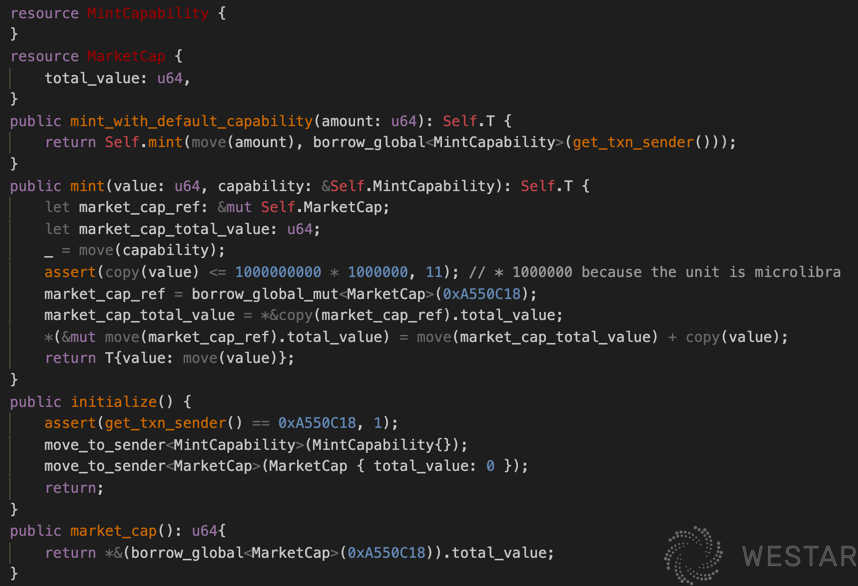
The above example has a mint method for minting coins, which actually ends up being a direct new LibraCoin. And this method has one parameter, capability, which represents a minting permission. And how is MintCapability generated? You can see the initialize method, which is created by a special account and held during the initialization of the creation block. As long as the account has MintCapability, it can be minted via the mint_with_default_capability method.
Let’s continue to see how LibraCoin can implement advanced transfers:
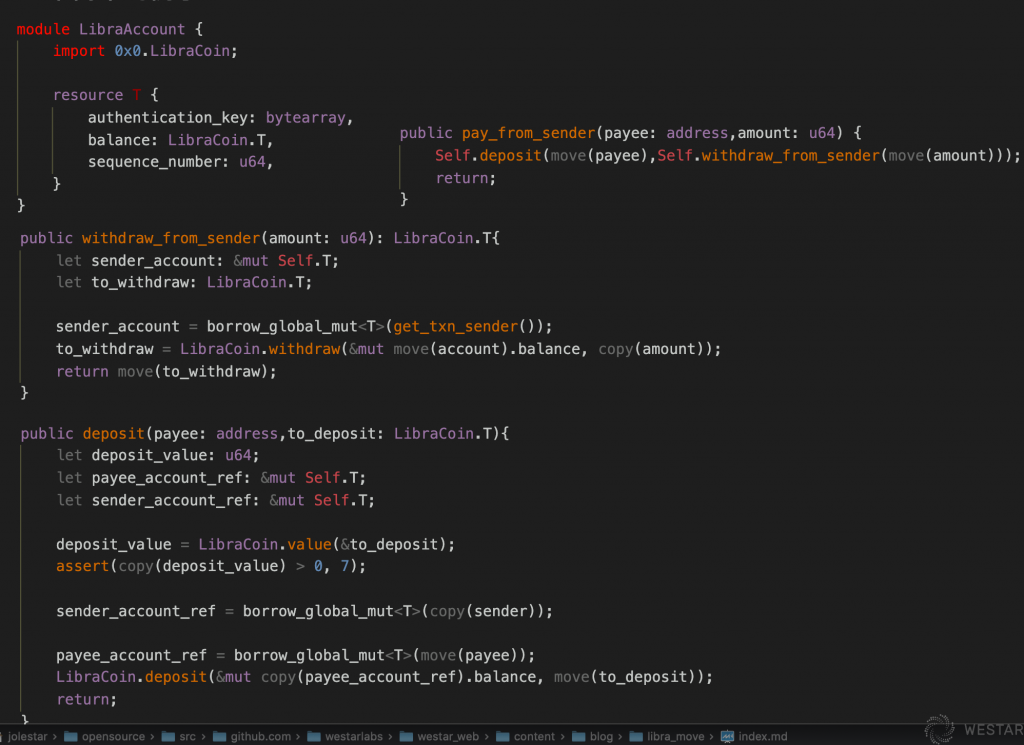
LibraAccount calls LibraCoin’s methods to manipulate its own balance field, thus enabling transfers. LibraCoin itself does not care about the advanced transfer logic. This way, layer upon layer is combined to construct advanced functionality.
To continue, look at one implementation of HashTimeLock:
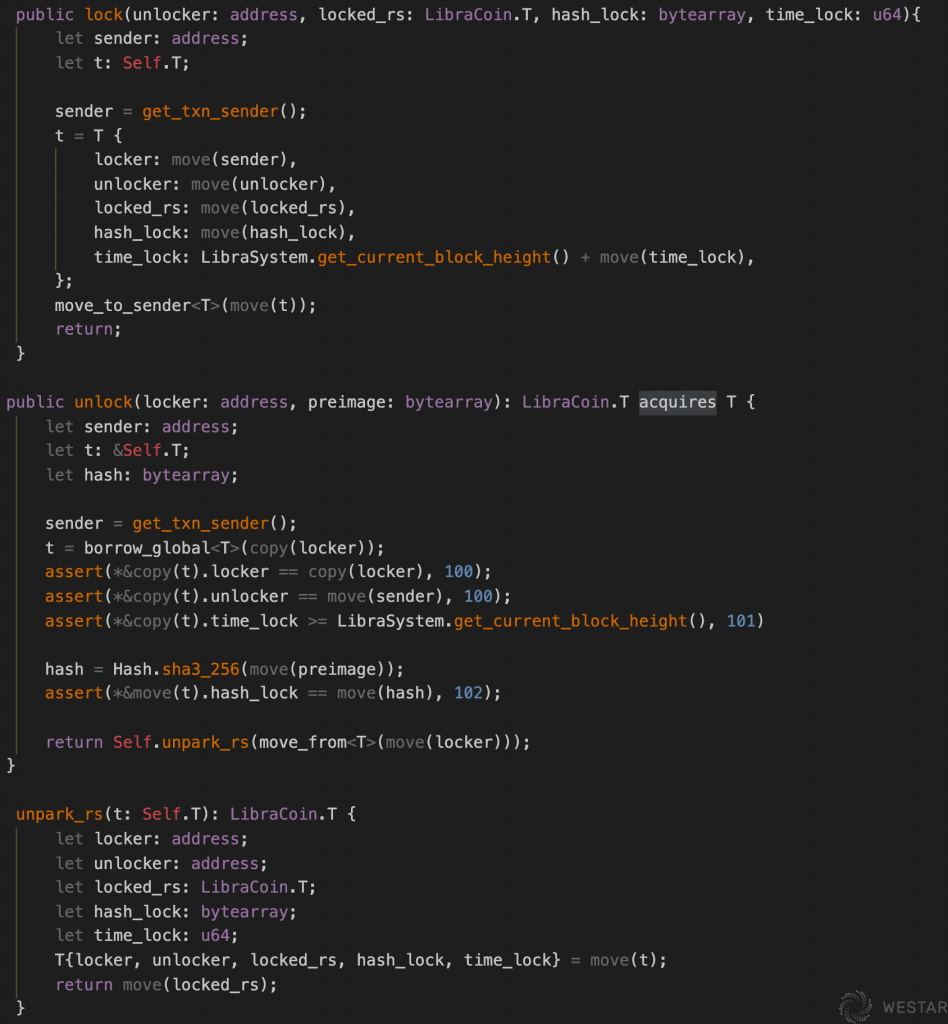
The lock method in the example encapsulates the asset in HashTimeLock.T and binds it to hash and time. unlock checks hash and time, and if correct, unlocks HashTimeLock.T and returns the encapsulated asset. The HashTimeLock contract does not care where the assets come from when locking and where the assets are stored after unlocking but can be defined by other contracts or written directly in the main script of the transaction, e.g:
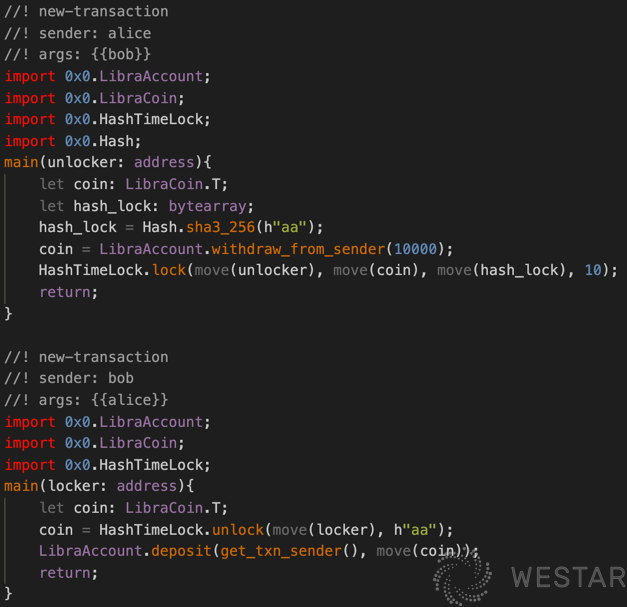
In this script, assets are taken out of LibraAccount and later charged back to LibraAccount. This can be defined by each transaction itself.
Interface is not supported: How to define standards
The previous example shows how Move assembles advanced functionality through assembly and visibility mechanisms, ensuring sufficient scaling without providing a mechanism for dynamic distribution. But how do you define a standard like ERC20 in Ethereum without a mechanism like Interface? How do you define the upper layer of the Defi protocol when different Token implementations are different?
Once I talked to the developer of Move about this issue, and I was impressed by what he said.
“When code is law, interfaces are a crime.” — tnowacki
In a world where code is law, an interface is a crime. This is because interfaces only define behavior, but do not care about the implementation. And when coding assets, users prefer that the operations associated with the assets themselves are deterministic.
He gives the example of a Token:
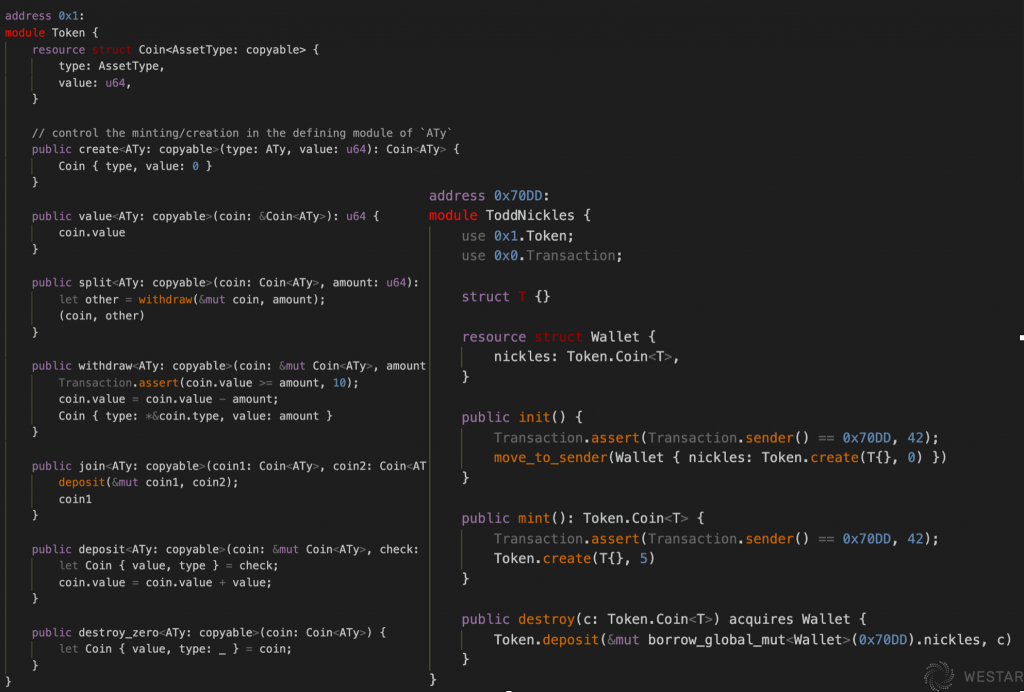
This example defines a Coin with a label through a generic type, and anyone can define a new Coin based on this Coin. the basic operations of the Coin are deterministic, but the issuer of the Coin can continue to encapsulate it at the upper level, deriving different characteristics. Such a mechanism ensures both deterministic behavior and sufficient scalability.

To use an analogy, the Token implementation in Solidity is similar to recording a ledger, while Move is similar to encapsulating an asset. When you go to rent something and pay a deposit, you will encounter two kinds of salesmen. The first type of salesperson aggregates the money together and records it in the ledger. The second type of salesperson then puts the money in a binder and keeps a name. When the first kind returns the money, the salesman needs to amend the ledger and then divide the deposit from the summed-up money and give it to the customer. The latter type, on the other hand, directly finds the corresponding deposit clip and gives it directly to the customer. The former kind is like Solidity, and the latter kind is like Move. the advantage of boxes is that you can box over boxes, it is easy to combine more complex boxes, and the books to combine can only be achieved by cross-referencing records between books.
Move’s state storage
The previous section describes the features of the Move language itself, and the contract programming language and its state storage mechanism are inextricably linked, so let’s explore Libra’s improvements in the state storage mechanism.

The above formula illustrates what data belongs to Libra’s GlobalState, the mapping between all accounts and account states. The key difference between this and Ethereum is that all of the states for each user is in their account path, rather than scattered across contracts.
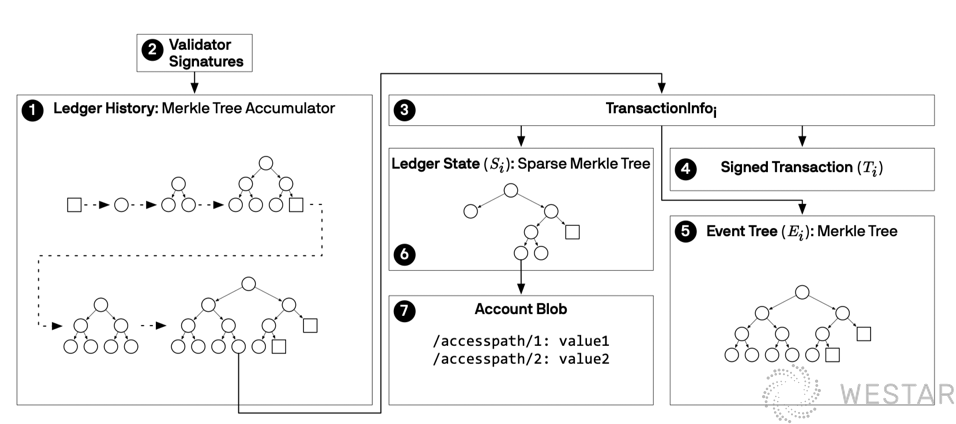
(Image source libra white paper)
The Sparse Merkle Tree in the figure above is equivalent to the Merkle Patricia Tree in Ethereum, which serves the same purpose, except for the difference in algorithm implementation. The Merkle Tree Accumulator is a new addition to Libra, where each block in Ethereum generates the root of a global state tree that is packed in the block header. In Libra, each transaction generates a root of the state tree, and then associates these roots with transaction information, and then accumulates them with an accumulator to generate a root of the accumulator, which is included in the block header. This accumulator is global and not for a particular block.
You can start by looking at the implementation of its accumulator (Accumulator):
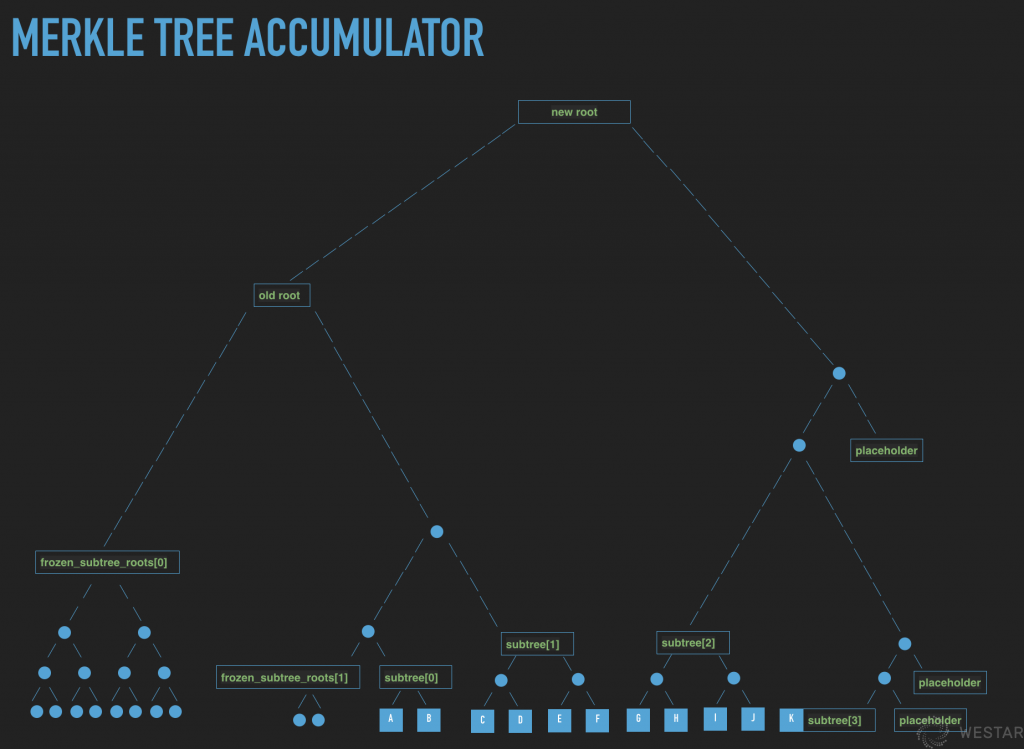
Accumulators, as the name implies, actually add up data to form a result, but also provide proof that the result contains a certain data. There are purely cryptographic implementations of accumulators (e.g., RSA Accumulator), but the computational efficiency is still difficult to meet the requirements of the application and the security proof is also difficult, so it is a more realistic approach to implement an accumulator through a Merkle tree.
The Merkle tree itself is a binary tree, if the leaf nodes are determined, the height of the tree is also determined, and it is easier to calculate the value of the root node. However, the leaf nodes of the accumulator have to grow dynamically, and the height of the tree is also growing dynamically. As shown above, the two subtrees on the left are already frozen, the values of their leaf nodes are no longer useful for the later calculation, and only the frozen root nodes are needed for the calculation. This algorithm has been discussed in the industry for quite some time, such as the Merkle Mountain Ranges algorithm discussed by the Bitcoin community. Due to space limitations, we will not analyze its algorithm here. The biggest role of this global accumulator is to provide global proof of the existence of the transaction execution; to prove that a transaction occurred on Ethereum and Bitcoin, one has to prove that the transaction was packed in a block and then prove that the block is actually on the chain.
Let’s take a look at its Sparse Merkle tree implementation:
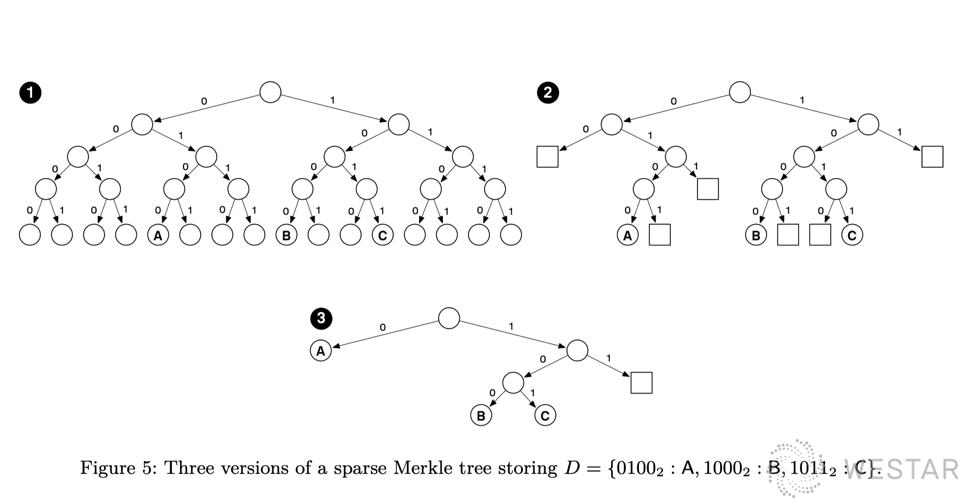
(Image source libra white paper)
Ethereum uses Merkle Tree to store state and provide state proofs. The first problem it encountered was that the height of Merkle Tree was too high, which made it expensive to compute and store, and generated large proofs. So it made an optimization, which is equivalent to turning a binary tree into a sixteen-fold tree. Libra has a similar idea, which is also to compress the paths. For example, 1 in the above figure is a complete binary tree, 2 optimizes the empty subtree, and 3 optimizes the middle node to shorten the path without divergence. It can be said to be similar to Ethereum’s Merkle Patricia Tree, but a unique advantage of the Sparse Merkle tree is that it can provide a proof of nonexistence. A more detailed analysis of the algorithm implementation can be found in @lerencao’s article Jellyfish Merkle Tree in Libra Blockchain.
Status of Move
Finally, a brief note on the status of Move:
- The above examples are partly Move IR (intermediate language) and partly Move source lang. Move source lang is the programming language for final developers, but it is not yet officially used in Libra, which still uses IR.
- Generic support is not yet finalized, and some of the examples above do not yet run directly.
- The Account state is now packaged into one big binary, not yet split into a two-level tree-like Ethereum.
- Incomplete support for set types, such as support for Map, etc.
- The space leasing mechanism is only theoretically designed and has not yet been realized.
Summary
To summarize the main improvements and implications of Move and Libra:
- FirstClass Resource, which allows assets to be not only programmable but also mapped to types in programs, provides a new model of programming
- All states of the same user are under the user path. This makes it technically possible to lease state space and to phase out user states. (Note: After a user state is eliminated, it can be stored back again by paying for it).
- Improvements and optimizations in the state storage mechanism, associating a global state to each transaction, can provide global proof of the transaction.
Libra’s design also has potential for layer2 mechanisms, mainly due to
- its unified asset programming model, which makes it easier to design generic layer2 schemes.
- the splitting of user state, which facilitates state migration between upstream and downstream chains
- the global proof mechanism, which facilitates layer2 arbitration.
I will discuss how to use these features to design a layer2 scheme in a future article.
Finally, to answer the opening question, the above innovations are indeed enough to support Move as a new programming language. The development of technology is to continuously introduce innovations to solve legacy problems, but at the same time bring new problems, and then trigger new innovations to advance in waves.